In machine learning, the backpropagation algorithm requires us to calculate the gradient of a loss or cost functions c:Rm×n→R. In doing so, the chain rule is applied and derivatives of intermediate matrix functions f:Rm×n→Rm×n have to be evaluated. This article aims to showcase a practical approach in evaluating such expressions and to further an understanding of the derivative and its use in backpropagation.
The derivative in higher dimensions
one dimension
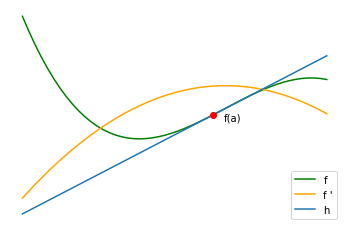
In the above, 1-dimensional example, it is common use the words derivative and slope interchangeably.
For example, by calculating the affine linear approximation h (also known as the first-order Taylor expansion of f in point a), we may write
h(x)=f(a)+f′(a)(x−a)
or by substitution:
h(a+t)=f(a)+f′(a)t(1)
and multiply our direction t with the function’s slope at point a.
For a single input and a single output the rate of change of the function directly corresponds to the slope of the graph.
In the multivariable, scalarfield case, where a scalar output depends on multiple inputs, we require a direction in which to measure the slope of the graph.
In order to further extend the notion of a derivative to higher dimensions, the multiplication in (1) could be seen as a linear function:
h(a+t)=f(a)+l(t)
where l(t)=f′(a)t is a linear mapping from R to R. Linear mappings from R to R are noted as L(R,R).
The derivative f′ then is a function R→L(R,R), which takes as input any arbitrary point a and yields the linear approximation l:R→R of f in point a.
scalar-by-vector
given a scalarfield, a function f:Rd→R, the derivative at point x is the best linear approximation L:Rd→R of f in point x, denoted as Df(x).
Df(x)(v)=∑i∂xi∂f(x)vi=(∇f(x))⊤v
where
∇f(x)=⎝⎜⎜⎛∂x1∂f(x)⋮∂xd∂f(x)⎠⎟⎟⎞
Reminder:
Df:Rdx→L(Rd,R)↦Df(x)
∈L(Rd,R)Df(x)=∈Rd∇f(x)
Df(x) is actually not ∇f(x), since the former is a linear function ∈L(Rd,R) (also called the dual of Rd) while the latter is a vector, an element of Rd. Because of the natural isomorphism L(Rd,R)≅Rd we may identify a linear map to R by a vector (by making use of the scalar-product). I will commit the occasional sin of mixing these notions, for example when writing ∇f(x)=Df(x)⊤, but it should be pointed out that these are essentially two different types of objects.
As an interesting side note, ...
the Riesz representation theorem, a fundamental theorem in functional analysis (a generalization of this idea) states that for any Hilbert space H (a vector space which is complete by its scalar-product induced norm), each dual element l∈H∗=L(H,R)) (the space of linearly continuous functionals) is representable by an element yl∈H of the space itself (even in the infinite dimensional setting). The application of the functional is equivalent to applying the scalar product to said element: l(x)=<yl,x>H. In the finite dimensional setting, every inner product space is complete and any linear function is continuous.
As before, via Taylor-Expansion, we can compute the first-order approximation of f by
f(x+tv)≈f(x)+Df(x)(v)t
Now you might be asking yourself whether to think of the derivative as a gradient or as a linear transformation. The idea of a gradient does not extend well to the multivariate case, i.e. a function f:Rd→Rd with multiple outputs, as it is not immediately an object of your input space anymore. The notion of a linear transformation however still holds. I will sometimes simply refer to derivatives as tensors, leaving the question of what type of object it is in the open.
vector-by-vector
In the multivariate case of f:Rd→Rn,f(x1,..,xd)=⎝⎜⎛f1(x1,..,xd)⋮fn(x1,..,xd)⎠⎟⎞ we are looking for a function Df that takes a vector as input, and returns a linear transformation L(Rd,Rn) which is representable by a matrix Rn×d and the application of the transformation being the equivalent of performing a matrix multiplication. Df≅Jf, the Jacobian of the function.
Thus, if an activation function is applied element-wise, the resulting derivative can also be computed element-wise. The application of the derivative can be written using the ⊙ Hadamard (element-wise) Product.
With the the stage set for the basic derivatives we can have a look at the basic idea of the backpropagation algorithm.
The idea behind backpropagation
When modelling a neural network for example we always need a loss function which we can minimize. The loss function is essentially a function f:Rd→R, it takes an input x and returns a scalar, the loss.
Note, that in the case of a neural network we might be minimizing over the weights W, then f is a function Rh2×h1→R, but this is practically the same as Rh2⋅h1→R. More on this later…
If f is differentiable, a step of the backpropagation algorithm is performed by computing xnew using the update rule xnew=x−λ∇f(x).
By Taylor-Expansion, we know that:
f(x+tv)=f(x)+Df(x)(v)t+o(t2)
where o(t2) is the error-term that decays quadratically in t (this means that for very small t this term will be of ‘lesser importance’ and the linear term will outweigh the quadratic t2-term).
Evaluating for xnew gives us:
This means that, since the squared norm ∥∇f(x)∥2 is positive, if we choose λ small enough, then the right-hand side −λ∥∇f(x)∥2+o(λ2) will be negative and thus
f(xnew)−f(x)⇒f(xnew)≤0≤f(x)
In neural networks one might have g:Rd→Rm as an intermediate function and f:Rm→R with our the cost being c=f(g(x)). Using the chain rule, we obtain:
which illustrates how the gradient propagated from “front to back”. Note that, since the derivatives have to be evaluated at their respective positions this also explains why we would want to store intermediate variables such as g in a cache as to not have to recompute these values every time.
scalar-by-matrix
One might think that a derivative of a scalar by a matrix would surely be a matrix as well, although following our definition of the derivative as a linear transformation, given f:Rm×n→R, we expect the derivative Df(x) to be ∈L(Rm×n,R) a linear function that takes as input a matrix and outputs a scalar.
Yet, using standard notation there is no matrix that converts another matrix into a scalar, as applying a matrix ‘from the right’ will look like matrix multiplication. A way to get around this problem would be to vectorize our input, keeping the order of the elements:
We might still decide that we want to write our derivative as a matrix. This is useful in the case that we want to calculate the ‘gradient’ for an update rule or when using the chain rule.
Thus far the matrix numerator-layout was used. Following this layout the derivative would have to be a n×m (transposed) matrix. To keep consistency in notation (which is important while applying the chain rule) I will refer to the gradient as ∂X∂f⊤ which has the same dimensions as X (m×n).
In the following I will assume that all derivatives are written in their matrix/tensorial form evaluated at their respective inputs and I will refer to the gradient (the transposed tensorial form) as
where “∙” means we calculate the element-wise product and then sum all entries. “∙” is basically the dot scalar-product if we were to vectorize matrices.
example of a scalar-matrix derivative:
An example is the (squared and rescaled) Frobenius matrix norm:
f:Rm×n→R,X↦21∥X∥F2=21ij∑xij2
∂X∂f(X)⊤≅⎝⎜⎛x11⋮xm1⋯⋱⋯x1n⋮xmn⎠⎟⎞=X
Df(1m×n)(Y)=1m×n∙Y=i,j∑yij
Here, I also want to note that depending on how we wish to contract a tensor
∂xij∂f≅Rm×n
this can be seen as an element ∈L(Rm,Rn), which corresponds to normal matrix-multiplication:
∂xij∂faj where a∈Rm
an element ∈L(Rn,Rm) (transposed matrix-multiplication):
bi∂xij∂f where b∈Rn
or an element ∈L(Rm×n,R), as we have seen:
∂xij∂fhij where H∈Rm×n
just by noting the indices along which we wish to contract a tensor. In this sense, the Einstein notation proves to be very elegant.
matrix-by-matrix
Assume we have a function A:Rp×q→Rm×n and c:Rm×n→R (this could be an activation layer and a cost function in a neural network).
Rp×qX→↦Rm×nA→↦Rc
Applying the chain rule:
∂xkl∂c=∂aij∂c∂xkl∂aij
We eventually come across the term
∂xkl∂aij
which, as the 4 indices indicate, is a rank-4 tensor.
Since we are interested in the gradient, we wish to calculate (again, sorry for the abuse of notation)
And R(p×q)×(m×n) is seen as a linear transformation L(Rm×n,Rp×q)
The single entries of the gradient are
∂xkl∂c=∂xkl∂aij∂aij∂c
Note: this formula encapsules everything one needs to know on how to calculate a derivative. However, keeping track of all those indices can get confusing. The way one could proceed to evaluate such an expression while keeping the spatial structure of the matrix is as follows.
Using the recently introduced notation:
∂xkl∂A∙∂A∂c⊤=∑∂xkl∂A⊙∂A∂c⊤
, where we sum over all free indices.
This means we can expand the tensor along the p×q dimensions and contract the other dimensions using the Hadamard product and summing. In almost the same fashion that we can calculate each entry of a matrix product by overlaying column and row vectors and then summing, here we overlay the matrix ∂A∂c⊤ with each ∂xkl∂A (also a matrix) and then sum.
Recalling how to apply the derivative ∂W∂Z⊤ to a matrix H (when training neuronal nets, this is typically dZ), we multiply each of the above submatrices with H element-wise and then sum all entries.